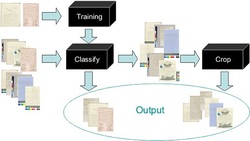
In my previous posts, I mentioned that the taxonomy is necessary to create navigation to content. If users know what they are looking for, they are going to search. If they don't know what they are looking for, they will look for ways to navigate to content, in other words, browse through content. Taxonomies can also be used as a method of filtering search results so that results are restricted to a selected node on the hierarchy.
Once documents have been classified, users tcan browse the document collection, using an expanding tree-view to represent the taxonomy structure.
When there are many documents involved, creating taxonomy could be time consuming. There are few tools on the market that provide automatic classification. Another use of the automatic classification is to automatically tag content with controlled metadata (also known as Automatic Metadata Tagging) to increase the quality of the search results.
The tools that provide automatic classification are: Autonomy, ClearForest, Documentum, Interwoven, Inxight, Moxomine, Open Text, Oracle, SmartLogic.
These tools can classify any type of text documents. Classification is either performed on a document repository or on a stream of incoming documents.
Here is how this software works. Example: "International Business Machines today announced that it would acquire Widget, Inc. A spokesperson for IBM said: "Big Blue will move quickly to ensure a speedy transition".
The software classifies concepts rather than words. Words are first stemmed, that is they are reduced to their root form. Next, stop words are being eliminated. These include words such as a, an, in, the - words that add little semantic information. Then, words with similar meanings are equated using thesaurus. For example, the words IBM, International Business Machines, and Big Blue are treated as equivalent.
Next, the software will use statistical or language processing techniques to identify noun phrases or concepts such as "red bicycle". Further, using thesaurus, these phrases are reduced to distinct concepts that will be associated with the document. In this example, there are 3 instances of IBM, 2 instances of acquisition (acquire, speedy transition), and 1 instance of Widget, Inc.
Approaches to Classification
Manual - requires individuals to assign each document to one or more categories. It can achieve a high degree of accuracy. However, it is labor intensive and therefore are more costly than automatic classification in the long run.
Rule-based - keywords or Boolean expressions are used to categorize a document. This is typically used when a few words can adequately describe a category. For example, if a collection of medical papers is to be classified according to a disease together with its scientific, common, and alternative names can be used to define the keywords for each category.
Supervised Learning - most approaches to automatic classification require a human expert to initiate a learning process by manually classifying or assigning a number of "training documents" to each category. This classification system first analyzes the statistical occurrences of each concept in the example documents and then constructs a model or "classifier for each category that is used to classify subsequent documents automatically. The system refines its model, in a sense "learning" the categories as documents are processed.
Unsupervised Learning - these systems identify both groups or clusters of related documents as well as the relationship between these clusters. Commonly referred as clustering, this approach eliminates the need for training sets because it does not require a preexisting taxonomy or category structure. However, clustering algorithms are not always good at selecting categories that are intuitive to users. On the other hand, clustering will often expose useful relationships and themes implicit in the collection that might be missed by a manual process. For this reasons, clustering generally works hand-in-hand with supervised learning techniques.
Each of approaches is optimal for a different situation. As a result, classification vendors are moving to support multiple methods.
Most real world implementations combine search, classification, and other techniques such as identifying similar documents to provide a complete information retrieval solution. Organizations having document repositories will generally benefit from a customized taxonomy.
Once documents are clustered, an administrator can first rearrange, expand or collapse the auto-suggested clusters or categories, and then give them intuitive names. The documents in the cluster serve as initial training sets for supervised-learning algorithms that will be used subsequently to refine the categories. The end result is a taxonomy and a set of topic models are fully customized for an organization's needs.
Building an extensive custom taxonomy can be a large expense. However, automated classification tools can reduce the taxonomy development and maintenance cost.
Organizations with document collections that span complex areas such as medicine, biotechnology, aerospace will have a large taxonomy. However, there are ways to refine taxonomy so it does not become an overwhelming task.
Together, enterprise search and classification provide an initial response to information overload.
Once documents have been classified, users tcan browse the document collection, using an expanding tree-view to represent the taxonomy structure.
When there are many documents involved, creating taxonomy could be time consuming. There are few tools on the market that provide automatic classification. Another use of the automatic classification is to automatically tag content with controlled metadata (also known as Automatic Metadata Tagging) to increase the quality of the search results.
The tools that provide automatic classification are: Autonomy, ClearForest, Documentum, Interwoven, Inxight, Moxomine, Open Text, Oracle, SmartLogic.
These tools can classify any type of text documents. Classification is either performed on a document repository or on a stream of incoming documents.
Here is how this software works. Example: "International Business Machines today announced that it would acquire Widget, Inc. A spokesperson for IBM said: "Big Blue will move quickly to ensure a speedy transition".
The software classifies concepts rather than words. Words are first stemmed, that is they are reduced to their root form. Next, stop words are being eliminated. These include words such as a, an, in, the - words that add little semantic information. Then, words with similar meanings are equated using thesaurus. For example, the words IBM, International Business Machines, and Big Blue are treated as equivalent.
Next, the software will use statistical or language processing techniques to identify noun phrases or concepts such as "red bicycle". Further, using thesaurus, these phrases are reduced to distinct concepts that will be associated with the document. In this example, there are 3 instances of IBM, 2 instances of acquisition (acquire, speedy transition), and 1 instance of Widget, Inc.
Approaches to Classification
Manual - requires individuals to assign each document to one or more categories. It can achieve a high degree of accuracy. However, it is labor intensive and therefore are more costly than automatic classification in the long run.
Rule-based - keywords or Boolean expressions are used to categorize a document. This is typically used when a few words can adequately describe a category. For example, if a collection of medical papers is to be classified according to a disease together with its scientific, common, and alternative names can be used to define the keywords for each category.
Supervised Learning - most approaches to automatic classification require a human expert to initiate a learning process by manually classifying or assigning a number of "training documents" to each category. This classification system first analyzes the statistical occurrences of each concept in the example documents and then constructs a model or "classifier for each category that is used to classify subsequent documents automatically. The system refines its model, in a sense "learning" the categories as documents are processed.
Unsupervised Learning - these systems identify both groups or clusters of related documents as well as the relationship between these clusters. Commonly referred as clustering, this approach eliminates the need for training sets because it does not require a preexisting taxonomy or category structure. However, clustering algorithms are not always good at selecting categories that are intuitive to users. On the other hand, clustering will often expose useful relationships and themes implicit in the collection that might be missed by a manual process. For this reasons, clustering generally works hand-in-hand with supervised learning techniques.
Each of approaches is optimal for a different situation. As a result, classification vendors are moving to support multiple methods.
Most real world implementations combine search, classification, and other techniques such as identifying similar documents to provide a complete information retrieval solution. Organizations having document repositories will generally benefit from a customized taxonomy.
Once documents are clustered, an administrator can first rearrange, expand or collapse the auto-suggested clusters or categories, and then give them intuitive names. The documents in the cluster serve as initial training sets for supervised-learning algorithms that will be used subsequently to refine the categories. The end result is a taxonomy and a set of topic models are fully customized for an organization's needs.
Building an extensive custom taxonomy can be a large expense. However, automated classification tools can reduce the taxonomy development and maintenance cost.
Organizations with document collections that span complex areas such as medicine, biotechnology, aerospace will have a large taxonomy. However, there are ways to refine taxonomy so it does not become an overwhelming task.
Together, enterprise search and classification provide an initial response to information overload.
 RSS Feed
RSS Feed
