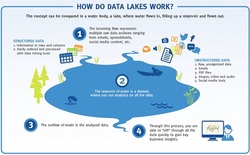
A data lake is a large storage repository and processing engine. Data lakes focus on storing disparate data and ignore how or why data is used, governed, defined and secured.
Benefits
The data lake concept hopes to solve information silos. Rather than having dozens of independently managed collections of data, you can combine these sources in the unmanaged data lake. The consolidation theoretically results in increased information use and sharing, while cutting costs through server and license reduction.
Data lakes can help resolve the nagging problem of accessibility and data integration. Using big data infrastructures, enterprises are starting to pull together increasing data volumes for analytics or simply to store for undetermined future use. Enterprises that must use enormous volumes and myriad varieties of data to respond to regulatory and competitive pressures are adopting data lakes. Data lakes are an emerging and powerful approach to the challenges of data integration as enterprises increase their exposure to mobile and cloud-based applications, the sensor-driven Internet of Things, and other aspects.
Currently the only viable example of a data lake is Apache Hadoop. Many companies also use cloud storage services such as Amazon S3 along with other open source tools such as Docker as a data lake. There is a gradual academic interest in the concept of data lakes.
Previous approaches to broad-based data integration have forced all users into a common predetermined schema, or data model. Unlike this monolithic view of a single enterprise-wide data model, the data lake relaxes standardization and defers modeling, resulting in a nearly unlimited potential for operational insight and data discovery. As data volumes, data variety, and metadata richness grow, so does the benefit.
Data lake is helping companies to collaboratively create models or views of the data and then manage incremental improvements to the metadata. Data scientists and business analysts using the newest lineage tracking tools such as Revelytix Loom or Apache Falcon to follow each other’s purpose-built data schemas. The lineage tracking metadata also is placed in the Hadoop Distributed File System (HDFS) which stores pieces of files across a distributed cluster of servers in the cloud where the metadata is accessible and can be collaboratively refined. Analytics drawn from the data lake become increasingly valuable as the metadata describing different views of the data accumulates.
Every industry has a potential data lake use case. A data lake can be a way to gain more visibility or to put an end to data silos. Many companies see data lakes as an opportunity to capture a 360-degree view of their customers or to analyze social media trends.
Some companies have built big data sandboxes for analysis by data scientists. Such sandboxes are somewhat similar to data lakes, albeit narrower in scope and purpose.
Relational data warehouses and their big price tags have long dominated complex analytics, reporting, and operations. However, their slow-changing data models and rigid field-to-field integration mappings are too brittle to support big data volume and variety. The vast majority of these systems also leave business users dependent on IT for even the smallest enhancements, due mostly to inelastic design, unmanageable system complexity, and low system tolerance for human error. The data lake approach helps to solve these problems.
Approach
Step number one in a data lake project is to pull all data together into one repository while giving minimal attention to creating schemas that define integration points between disparate data sets. This approach facilitates access, but the work required to turn that data into actionable insights is a substantial challenge. While integrating the data takes place at the Hadoop layer, contextualizing the metadata takes place at schema creation time.
Integrating data involves fewer steps because data lakes don’t enforce a rigid metadata schema as do relational data warehouses. Instead, data lakes support a concept known as late binding, or schema on read, in which users build custom schema into their queries. Data is bound to a dynamic schema created upon query execution. The late-binding principle shifts the data modeling from centralized data warehousing teams and database administrators, who are often remote from data sources, to localized teams of business analysts and data scientists, who can help create flexible, domain-specific context. For those accustomed to SQL, this shift opens a whole new world.
In this approach, the more is known about the metadata, the easier it is to query. Pre-tagged data, such as Extensible Markup Language (XML), JavaScript Object Notation (JSON), or Resource Description Framework (RDF), offers a starting point and is highly useful in implementations with limited data variety. In most cases, however, pre-tagged data is a small portion of incoming data formats.
Lessons Learned
Some data lake initiatives have not succeeded, producing instead more silos or empty sandboxes. Given the risk, everyone is proceeding cautiously. There are companies who create big data graveyards, dumping everything into them and hoping to do something with it down the road.
Companies would avoid creating big data graveyards by developing and executing a solid strategic plan that applies the right technology and methods to the problem. Hadoop and the NoSQL (Not only SQL) category of databases have potential, especially when they can enable a single enterprise-wide repository and provide access to data previously trapped in silos. The main challenge is not creating a data lake, but taking advantage of the opportunities it presents. A means of creating, enriching, and managing semantic metadata incrementally is essential.
Data Flow in the Data Lake
The data lake loads extracts, irrespective of its format, into a big data store. Metadata is decoupled from its underlying data and stored independently. This enables flexibility for multiple end-user perspectives and maturing semantics.
How a Data Lake Matures
Sourcing new data into the lake can occur gradually and will not impact existing models. The lake starts with raw data, and it matures as more data flows in, as users and machines build up metadata, and as user adoption broadens. Ambiguous and competing terms eventually converge into a shared understanding (that is, semantics) within and across business domains. Data maturity results as a natural outgrowth of the ongoing user interaction and feedback at the metadata management layer, interaction that continually refines the lake and enhances discovery.
With the data lake, users can take what is relevant and leave the rest. Individual business domains can mature independently and gradually. Perfect data classification is not required. Users throughout the enterprise can see across all disciplines, not limited by organizational silos or rigid schema.
Data Lake Maturity
The data lake foundation includes a big data repository, metadata management, and an application framework to capture and contextualize end-user feedback. The increasing value of analytics is then directly correlated in increase in user adoption across the enterprise.
Risks
Data lakes therefore carry risks. The most important is the inability to determine data quality or the lineage of findings by other analysts or users that have found value, previously, in using the same data in the lake. By its definition, a data lake accepts any data, without oversight or governance. Without descriptive metadata and a mechanism to maintain it, the data lake risks turning into a data swamp. And without metadata, every subsequent use of data means analysts start from scratch.
Another risk is security and access control. Data can be placed into the data lake with no oversight of the contents. Many data lakes are being used for data whose privacy and regulatory requirements are likely to represent risk exposure. The security capabilities of central data lake technologies are still in the beginning stage.
Finally, performance aspects should not be overlooked. Tools and data interfaces simply cannot perform at the same level against a general-purpose store as they can against optimized and purpose-built infrastructure.
Careful planning and organization of data lake strategy is required to make this project a success.
Benefits
The data lake concept hopes to solve information silos. Rather than having dozens of independently managed collections of data, you can combine these sources in the unmanaged data lake. The consolidation theoretically results in increased information use and sharing, while cutting costs through server and license reduction.
Data lakes can help resolve the nagging problem of accessibility and data integration. Using big data infrastructures, enterprises are starting to pull together increasing data volumes for analytics or simply to store for undetermined future use. Enterprises that must use enormous volumes and myriad varieties of data to respond to regulatory and competitive pressures are adopting data lakes. Data lakes are an emerging and powerful approach to the challenges of data integration as enterprises increase their exposure to mobile and cloud-based applications, the sensor-driven Internet of Things, and other aspects.
Currently the only viable example of a data lake is Apache Hadoop. Many companies also use cloud storage services such as Amazon S3 along with other open source tools such as Docker as a data lake. There is a gradual academic interest in the concept of data lakes.
Previous approaches to broad-based data integration have forced all users into a common predetermined schema, or data model. Unlike this monolithic view of a single enterprise-wide data model, the data lake relaxes standardization and defers modeling, resulting in a nearly unlimited potential for operational insight and data discovery. As data volumes, data variety, and metadata richness grow, so does the benefit.
Data lake is helping companies to collaboratively create models or views of the data and then manage incremental improvements to the metadata. Data scientists and business analysts using the newest lineage tracking tools such as Revelytix Loom or Apache Falcon to follow each other’s purpose-built data schemas. The lineage tracking metadata also is placed in the Hadoop Distributed File System (HDFS) which stores pieces of files across a distributed cluster of servers in the cloud where the metadata is accessible and can be collaboratively refined. Analytics drawn from the data lake become increasingly valuable as the metadata describing different views of the data accumulates.
Every industry has a potential data lake use case. A data lake can be a way to gain more visibility or to put an end to data silos. Many companies see data lakes as an opportunity to capture a 360-degree view of their customers or to analyze social media trends.
Some companies have built big data sandboxes for analysis by data scientists. Such sandboxes are somewhat similar to data lakes, albeit narrower in scope and purpose.
Relational data warehouses and their big price tags have long dominated complex analytics, reporting, and operations. However, their slow-changing data models and rigid field-to-field integration mappings are too brittle to support big data volume and variety. The vast majority of these systems also leave business users dependent on IT for even the smallest enhancements, due mostly to inelastic design, unmanageable system complexity, and low system tolerance for human error. The data lake approach helps to solve these problems.
Approach
Step number one in a data lake project is to pull all data together into one repository while giving minimal attention to creating schemas that define integration points between disparate data sets. This approach facilitates access, but the work required to turn that data into actionable insights is a substantial challenge. While integrating the data takes place at the Hadoop layer, contextualizing the metadata takes place at schema creation time.
Integrating data involves fewer steps because data lakes don’t enforce a rigid metadata schema as do relational data warehouses. Instead, data lakes support a concept known as late binding, or schema on read, in which users build custom schema into their queries. Data is bound to a dynamic schema created upon query execution. The late-binding principle shifts the data modeling from centralized data warehousing teams and database administrators, who are often remote from data sources, to localized teams of business analysts and data scientists, who can help create flexible, domain-specific context. For those accustomed to SQL, this shift opens a whole new world.
In this approach, the more is known about the metadata, the easier it is to query. Pre-tagged data, such as Extensible Markup Language (XML), JavaScript Object Notation (JSON), or Resource Description Framework (RDF), offers a starting point and is highly useful in implementations with limited data variety. In most cases, however, pre-tagged data is a small portion of incoming data formats.
Lessons Learned
Some data lake initiatives have not succeeded, producing instead more silos or empty sandboxes. Given the risk, everyone is proceeding cautiously. There are companies who create big data graveyards, dumping everything into them and hoping to do something with it down the road.
Companies would avoid creating big data graveyards by developing and executing a solid strategic plan that applies the right technology and methods to the problem. Hadoop and the NoSQL (Not only SQL) category of databases have potential, especially when they can enable a single enterprise-wide repository and provide access to data previously trapped in silos. The main challenge is not creating a data lake, but taking advantage of the opportunities it presents. A means of creating, enriching, and managing semantic metadata incrementally is essential.
Data Flow in the Data Lake
The data lake loads extracts, irrespective of its format, into a big data store. Metadata is decoupled from its underlying data and stored independently. This enables flexibility for multiple end-user perspectives and maturing semantics.
How a Data Lake Matures
Sourcing new data into the lake can occur gradually and will not impact existing models. The lake starts with raw data, and it matures as more data flows in, as users and machines build up metadata, and as user adoption broadens. Ambiguous and competing terms eventually converge into a shared understanding (that is, semantics) within and across business domains. Data maturity results as a natural outgrowth of the ongoing user interaction and feedback at the metadata management layer, interaction that continually refines the lake and enhances discovery.
With the data lake, users can take what is relevant and leave the rest. Individual business domains can mature independently and gradually. Perfect data classification is not required. Users throughout the enterprise can see across all disciplines, not limited by organizational silos or rigid schema.
Data Lake Maturity
The data lake foundation includes a big data repository, metadata management, and an application framework to capture and contextualize end-user feedback. The increasing value of analytics is then directly correlated in increase in user adoption across the enterprise.
Risks
Data lakes therefore carry risks. The most important is the inability to determine data quality or the lineage of findings by other analysts or users that have found value, previously, in using the same data in the lake. By its definition, a data lake accepts any data, without oversight or governance. Without descriptive metadata and a mechanism to maintain it, the data lake risks turning into a data swamp. And without metadata, every subsequent use of data means analysts start from scratch.
Another risk is security and access control. Data can be placed into the data lake with no oversight of the contents. Many data lakes are being used for data whose privacy and regulatory requirements are likely to represent risk exposure. The security capabilities of central data lake technologies are still in the beginning stage.
Finally, performance aspects should not be overlooked. Tools and data interfaces simply cannot perform at the same level against a general-purpose store as they can against optimized and purpose-built infrastructure.
Careful planning and organization of data lake strategy is required to make this project a success.
 RSS Feed
RSS Feed
