
In my previous post on DITA, I mentioned that DITA, Darwin Information Typing Architecture, is an XML-based architecture for authoring, producing, and delivering information. In this post, I am going to describe more details about DITA and how it is used in content management.
At the heart of DITA, representing the generic building block of a topic-oriented information architecture, is an XML document type definition (DTD) called the topic DTD. The point of the XML-based Darwin Information Typing Architecture (DITA) is to create modular technical documents that are easy to reuse with varied display and delivery mechanisms.
Main features of the DITA architecture
As the "Architecture" part of DITA's name suggests, DITA has unifying features that serve to organize and integrate information:
Topic orientation. The highest standard structure in DITA is the topic. Any higher structure than a topic is usually part of the processing context for a topic, such as a print-organizing structure or the navigation for a set of topics.
Reuse. A principal goal for DITA has been to reduce the practice of copying content from one place to another as a way of reusing content. Reuse within DITA occurs on two levels:
Topic reuse. Because of the non-nesting structure of topics, a topic can be reused in any topic-like context.
Content reuse. DITA provides each element with a conref attribute that can point to any other equivalent element in the same or any other topic.
Specialization. Any DITA element can be extended into a new element.
Topic specialization. Applied to topic structures, specialization is a natural way to extend the generic topic into new information types (or infotypes), which in turn can be extended into more specific instantiations of information structures. For example, a recipe, a material safety data sheet, and an encyclopedia article are all potential derivations from a common reference topic.
Domain specialization. Using the same specialization principle, the element vocabulary within a generic topic can be extended by introducing elements that reflect a particular information domain served by those topics. For example, a keyword can be extended as a unit of weight in a recipe, as a part name in a hardware reference, or as a variable in a programming reference.
Property-based processing. The DITA model provides metadata and attributes that can be used to associate or filter the content of DITA topics with applications such as content management systems, search engines, etc.
Extensive metadata to make topics easier to find. The DITA model for metadata supports the standard categories for the Dublin Core Metadata Initiative. In addition, the DITA metadata enables many different content management approaches to be applied to its content.
Universal properties. Most elements in the topic DTD contain a set of universal attributes that enable the elements to be used as selectors, filters, content referencing infrastructure, and multi-language support.
Taking advantage of existing tags and tools. Rather than being a radical departure from the familiar, DITA builds on well-accepted sets of tags and can be used with standard XML tools.
Leveraging popular language subsets. The core elements in DITA's topic DTD borrow from HTML and XHTML, using familiar element names like p, ol, ul, and dl within an HTML-like topic structure. In fact, DITA topics can be written, like HTML for rendering directly in a browser.
Leveraging popular and well-supported tools. The XML processing model is widely supported by a number of vendors and translates well to the design features of the XSLT and CSS stylesheet languages defined by the World Wide Web Consortium and supported in many transformation tools, editors, and browsers.
At the heart of DITA, representing the generic building block of a topic-oriented information architecture, is an XML document type definition (DTD) called the topic DTD. The point of the XML-based Darwin Information Typing Architecture (DITA) is to create modular technical documents that are easy to reuse with varied display and delivery mechanisms.
Main features of the DITA architecture
As the "Architecture" part of DITA's name suggests, DITA has unifying features that serve to organize and integrate information:
Topic orientation. The highest standard structure in DITA is the topic. Any higher structure than a topic is usually part of the processing context for a topic, such as a print-organizing structure or the navigation for a set of topics.
Reuse. A principal goal for DITA has been to reduce the practice of copying content from one place to another as a way of reusing content. Reuse within DITA occurs on two levels:
Topic reuse. Because of the non-nesting structure of topics, a topic can be reused in any topic-like context.
Content reuse. DITA provides each element with a conref attribute that can point to any other equivalent element in the same or any other topic.
Specialization. Any DITA element can be extended into a new element.
Topic specialization. Applied to topic structures, specialization is a natural way to extend the generic topic into new information types (or infotypes), which in turn can be extended into more specific instantiations of information structures. For example, a recipe, a material safety data sheet, and an encyclopedia article are all potential derivations from a common reference topic.
Domain specialization. Using the same specialization principle, the element vocabulary within a generic topic can be extended by introducing elements that reflect a particular information domain served by those topics. For example, a keyword can be extended as a unit of weight in a recipe, as a part name in a hardware reference, or as a variable in a programming reference.
Property-based processing. The DITA model provides metadata and attributes that can be used to associate or filter the content of DITA topics with applications such as content management systems, search engines, etc.
Extensive metadata to make topics easier to find. The DITA model for metadata supports the standard categories for the Dublin Core Metadata Initiative. In addition, the DITA metadata enables many different content management approaches to be applied to its content.
Universal properties. Most elements in the topic DTD contain a set of universal attributes that enable the elements to be used as selectors, filters, content referencing infrastructure, and multi-language support.
Taking advantage of existing tags and tools. Rather than being a radical departure from the familiar, DITA builds on well-accepted sets of tags and can be used with standard XML tools.
Leveraging popular language subsets. The core elements in DITA's topic DTD borrow from HTML and XHTML, using familiar element names like p, ol, ul, and dl within an HTML-like topic structure. In fact, DITA topics can be written, like HTML for rendering directly in a browser.
Leveraging popular and well-supported tools. The XML processing model is widely supported by a number of vendors and translates well to the design features of the XSLT and CSS stylesheet languages defined by the World Wide Web Consortium and supported in many transformation tools, editors, and browsers.
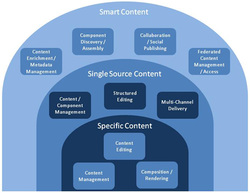
Typed topics are easily managed within content management systems as reusable, stand-alone units of information. For example, selected topics can be gathered, arranged, and processed within a delivery context to provide a variety of deliverables to varied audiences. These deliverables might be a booklet, a web site, a specification, etc.
At the center of these content management systems are fundamental XML technologies for creating modular content, managing it as discrete chunks, and publishing it in an organized fashion. These are the basic technologies for "one source, one output" applications, sometimes referred to as Singe Source Publishing (SSP) systems.
The innermost ring contains capabilities that are needed even when using a dedicated word processor or layout tool, including editing, rendering, and some limited content storage capabilities. In the middle ring are the technologies that enable single-sourcing content components for reuse in multiple outputs. They include a more robust content management environment, often with workflow management tools, as well as multi-channel formatting and delivery capabilities and structured editing tools. The outermost ring includes the technologies for smart content applications.
It is good to note that smart content solutions rely on structured editing, component management, and multi-channel delivery as foundational capabilities, augmented with content enrichment, topic component assembly, and social publishing capabilities across a distributed network.
Content Enrichment/Metadata Management: Once a descriptive metadata taxonomy is created or adopted, its use for content enrichment will depend on tools for analyzing and/or applying the metadata. These can be manual dialogs, automated scripts and crawlers, or a combination of approaches. Automated scripts can be created to interrogate the content to determine what it is about and to extract key information for use as metadata. Automated tools are efficient and scalable, but generally do not apply metadata with the same accuracy as manual processes. Manual processes, while ensuring better enrichment, are labor intensive and not scalable for large volumes of content. A combination of manual and automated processes and tools is the most likely approach in a smart content environment. Taxonomies may be extensible over time and can require administrative tools for editorial control and term management.
Component Discovery/Assembly: Once data has been enriched, tools for searching and selecting content based on the enrichment criteria will enable more precise discovery and access. Search mechanisms can use metadata to improve search results compared to full text searching. Information architects and content managers can use search to discover what content exists, and what still needs to be developed to proactively manage and monitor the content. These same discovery and search capabilities can be used to automatically create delivery maps and dynamically assemble content organized using them.
Distributed Collaboration/Social Publishing: Componentized information lends itself to a more granular update and maintenance process, enabling several users to simultaneously access topics that may appear in a single deliverable form to reduce schedules. Subject matter experts, both remote and local, may be included in review and content creation processes at key steps. Users of the information may want to "self-organize" the content of greatest interest to them, and even augment or comment upon specific topics. A distributed social publishing capability will enable a broader range of contributors to participate in the creation, review and updating of content in new ways.
Federated Content Management/Access: Smart content solutions can integrate content without duplicating it in multiple places, rather accessing it across the network in the original storage repository. This federated content approach requires the repositories to have integration capabilities to access content stored in other systems, platforms, and environments. A federated system architecture will rely on interoperability standards (such as CMIS), system agnostic expressions of data models (such as XML Schemas), and a robust network infrastructure (such as the Internet).
These capabilities address a broader range of business activity and therefore fulfill more business requirements than single-source content solutions. Assessing your ability to implement these capabilities is essential in evaluating your organizations readiness for a smart content solution.
At the center of these content management systems are fundamental XML technologies for creating modular content, managing it as discrete chunks, and publishing it in an organized fashion. These are the basic technologies for "one source, one output" applications, sometimes referred to as Singe Source Publishing (SSP) systems.
The innermost ring contains capabilities that are needed even when using a dedicated word processor or layout tool, including editing, rendering, and some limited content storage capabilities. In the middle ring are the technologies that enable single-sourcing content components for reuse in multiple outputs. They include a more robust content management environment, often with workflow management tools, as well as multi-channel formatting and delivery capabilities and structured editing tools. The outermost ring includes the technologies for smart content applications.
It is good to note that smart content solutions rely on structured editing, component management, and multi-channel delivery as foundational capabilities, augmented with content enrichment, topic component assembly, and social publishing capabilities across a distributed network.
Content Enrichment/Metadata Management: Once a descriptive metadata taxonomy is created or adopted, its use for content enrichment will depend on tools for analyzing and/or applying the metadata. These can be manual dialogs, automated scripts and crawlers, or a combination of approaches. Automated scripts can be created to interrogate the content to determine what it is about and to extract key information for use as metadata. Automated tools are efficient and scalable, but generally do not apply metadata with the same accuracy as manual processes. Manual processes, while ensuring better enrichment, are labor intensive and not scalable for large volumes of content. A combination of manual and automated processes and tools is the most likely approach in a smart content environment. Taxonomies may be extensible over time and can require administrative tools for editorial control and term management.
Component Discovery/Assembly: Once data has been enriched, tools for searching and selecting content based on the enrichment criteria will enable more precise discovery and access. Search mechanisms can use metadata to improve search results compared to full text searching. Information architects and content managers can use search to discover what content exists, and what still needs to be developed to proactively manage and monitor the content. These same discovery and search capabilities can be used to automatically create delivery maps and dynamically assemble content organized using them.
Distributed Collaboration/Social Publishing: Componentized information lends itself to a more granular update and maintenance process, enabling several users to simultaneously access topics that may appear in a single deliverable form to reduce schedules. Subject matter experts, both remote and local, may be included in review and content creation processes at key steps. Users of the information may want to "self-organize" the content of greatest interest to them, and even augment or comment upon specific topics. A distributed social publishing capability will enable a broader range of contributors to participate in the creation, review and updating of content in new ways.
Federated Content Management/Access: Smart content solutions can integrate content without duplicating it in multiple places, rather accessing it across the network in the original storage repository. This federated content approach requires the repositories to have integration capabilities to access content stored in other systems, platforms, and environments. A federated system architecture will rely on interoperability standards (such as CMIS), system agnostic expressions of data models (such as XML Schemas), and a robust network infrastructure (such as the Internet).
These capabilities address a broader range of business activity and therefore fulfill more business requirements than single-source content solutions. Assessing your ability to implement these capabilities is essential in evaluating your organizations readiness for a smart content solution.
 RSS Feed
RSS Feed
